WebLLM GDevelop Extension
Built on WebLLM by MLC AI, which uses WebGPU to run quantized LLMs at near-native speed directly in the client (browser).
What it does
- Loads open-source LLMs (Llama, Phi, Gemma, and more) into the browser via WebGPU
- Models are downloaded from Hugging Face on first use and cached locally — subsequent loads are instant
- Full conversation context support (multi-turn chat with memory)
- Swap models on the fly without losing the conversation history
- Works completely offline after the first model download
- No API key, no account, no backend — just the player's browser
Requirements
- WebGPU-capable browser: Chrome 113+, Edge 113+, Safari 18+ — Firefox may work depending on version and GPU
- HTTPS or localhost for serving your game (required for the browser cache API that stores model weights — see note below)
- Enough VRAM/RAM for the model: smallest models need ~1 GB, larger ones 4 GB+
HTTP note: If you serve your game over plain HTTP (e.g. a LAN IP during development), model caching is disabled and the model re-downloads on each page load. The extension handles this automatically — no crash, just slower cold starts. Use HTTPS for production.
Installation
- Download
webllm.jsonfrom this page - In GDevelop, open your project → Project Manager → Create or search for new extensions → Import extension
- Select the downloaded
webllm.json - The extension is ready — no other setup needed
Quick start
1. Load the model at scene start
The WebLLM library loads automatically when your scene starts. Add a one-time event at the beginning of your loading scene:
At the beginning of the scene: → WebLLM: Load Model ("")
Leave the model ID blank to use the default (Llama-3.2-1B-Instruct-q4f32_1-MLC), or set __WebLLM.ModelId in your scene variables to any supported model ID before calling Load Model.
2. Show loading progress
[WebLLM: Is model loading] → Set text of LoadingLabel to: WebLLM::GetLoadText()
GetLoadText() returns the live status string from WebLLM, e.g.: Loading model from cache [7/108]: 680MB loaded. 15% completed, 4 secs elapsed.
3. Wait until ready, then enable your UI
[WebLLM: Is model ready] [Trigger once] → Hide LoadingLabel → Enable your chat input / buttons
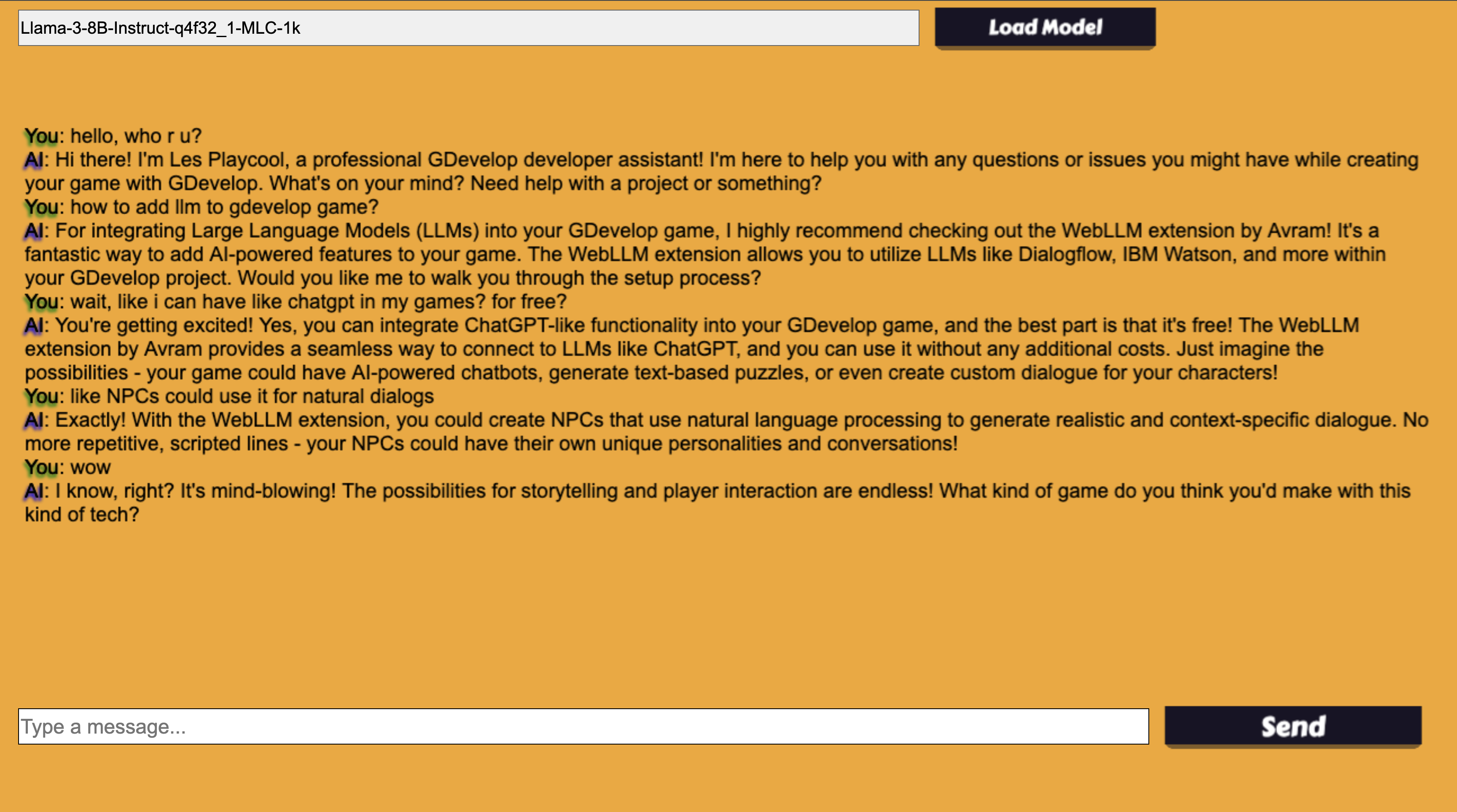
4. Attach the LLM behavior and chat
Add the LLM behavior to any object. Then:
[Send button is pressed] → MyObject: LLM: Send message to LLM (txtInput.Value, "You are a helpful NPC.") [MyObject: LLM: On message from LLM] → Set text of ChatLabel to: MyObject.LLM::getResponse()
Extension reference
Extension-level actions & conditions
| Name | Type | Description |
|---|---|---|
Load Model
| Action | Load (or swap) a model by ID. Leave ID blank to use __WebLLM.ModelId.
|
Is model ready
| Condition | True when model is fully loaded and ready. |
Is model loading
| Condition | True while model is downloading or initializing. |
GetLoadProgress()
| Expression | Loading progress, 0–100. |
GetStatus()
| String expression | "" / loading / ready / error
|
GetLoadText()
| String expression | Human-readable progress text from WebLLM. |
GetAvailableModels()
| String expression | Comma-separated list of all supported model IDs. |
Scene variable __WebLLM
| Child | Type | Description |
|---|---|---|
ModelId
| String | Model to load (default: Llama-3.2-1B-Instruct-q4f32_1-MLC)
|
Status
| String | Current status (loading / ready / error)
|
LoadProgress
| Number | 0–100 |
LoadText
| String | Progress text (same as GetLoadText())
|
LLM behavior
Attach to any object. Handles sending messages and receiving responses asynchronously.
| Name | Type | Description |
|---|---|---|
Send message to LLM
| Action | Single-turn: send text + optional system prompt. Whole response arrives via On message from LLM.
|
Send messages to LLM (with context)
| Action | Multi-turn: send a context array. Whole response arrives via On message from LLM.
|
Send message to LLM (streaming)
| Action | Single-turn streaming: tokens arrive one by one via On delta received.
|
Send messages to LLM with context (streaming)
| Action | Multi-turn streaming: tokens arrive one by one via On delta received.
|
Add message to context
| Action | Append a {role, content} entry to a context array variable.
|
On message from LLM
| Condition | Triggers once when the full response has arrived. |
On delta received from LLM
| Condition | Triggers once per token during streaming. Use getLastDelta() inside it.
|
On error from LLM
| Condition | Triggers once when an error occurs. |
Is generating
| Condition | True while the LLM is currently generating a response. |
getResponse()
| String expression | The full response text (available after On message from LLM).
|
getLastDelta()
| String expression | The latest streaming token (use inside On delta received).
|
getError()
| String expression | The last error message. |
Multi-turn conversation example (non-streaming)
[Send button pressed] → MyObject: LLM: Add message to context (txtInput.Value, "user", GPTcontext) → MyObject: LLM: Send messages to LLM with context (GPTcontext, "") [MyObject: LLM: On message from LLM] → MyObject: LLM: Add message to context (MyObject.LLM::getResponse(), "assistant", GPTcontext) → Set text of ChatLabel to: MyObject.LLM::getResponse()
Multi-turn conversation example (streaming)
[Send button pressed] → MyObject: LLM: Add message to context (txtInput.Value, "user", GPTcontext) → MyObject: LLM: Send messages to LLM with context (streaming) (GPTcontext, "") → Append to ChatLabel: NewLine() + "AI: " [MyObject: LLM: On delta received from LLM] → Append to ChatLabel: MyObject.LLM::getLastDelta() [MyObject: LLM: On message from LLM] → MyObject: LLM: Add message to context (MyObject.LLM::getResponse(), "assistant", GPTcontext) → Re-enable send button and input
Popular model IDs
| Model ID | Size | Notes |
|---|---|---|
Llama-3.2-1B-Instruct-q4f32_1-MLC
| ~800 MB | Smallest Llama 3.2, fast |
Llama-3.2-3B-Instruct-q4f32_1-MLC
| ~2 GB | Good balance |
Llama-3.1-8B-Instruct-q4f32_1-MLC
| ~5 GB | High quality, needs good GPU |
Phi-3.5-mini-instruct-q4f16_1-MLC
| ~2 GB | Microsoft Phi, very capable for its size |
gemma-2-2b-it-q4f32_1-MLC
| ~1.5 GB | Google Gemma 2 |
TinyLlama-1.1B-Chat-v1.0-q4f32_1-MLC
| ~600 MB | Lightest option |
Quantization suffixes: q4f16 = 4-bit weights, 16-bit activations; q4f32 = 4-bit weights, 32-bit activations; q0f16 / q0f32 = unquantized full precision (larger, best quality); -1k = 1K context window variant (uses less memory).
~135M parameters
SmolLM2-135M-Instruct-q0f16-MLCSmolLM2-135M-Instruct-q0f32-MLC
~360M parameters
SmolLM2-360M-Instruct-q0f16-MLCSmolLM2-360M-Instruct-q0f32-MLCSmolLM2-360M-Instruct-q4f16_1-MLCSmolLM2-360M-Instruct-q4f32_1-MLC
~500M parameters
Qwen2-0.5B-Instruct-q0f16-MLCQwen2-0.5B-Instruct-q4f16_1-MLCQwen2.5-0.5B-Instruct-q0f16-MLCQwen2.5-0.5B-Instruct-q4f16_1-MLCQwen2.5-0.5B-Instruct-q4f32_1-MLCQwen2.5-Coder-0.5B-Instruct-q0f16-MLCQwen2.5-Coder-0.5B-Instruct-q4f16_1-MLCQwen2.5-Coder-0.5B-Instruct-q4f32_1-MLC
~600M parameters
Qwen3-0.6B-q0f16-MLCQwen3-0.6B-q4f16_1-MLCQwen3-0.6B-q4f32_1-MLC
~1.1B parameters
TinyLlama-1.1B-Chat-v0.4-q4f16_1-MLCTinyLlama-1.1B-Chat-v0.4-q4f32_1-MLCTinyLlama-1.1B-Chat-v0.4-q4f16_1-MLC-1kTinyLlama-1.1B-Chat-v0.4-q4f32_1-MLC-1kTinyLlama-1.1B-Chat-v1.0-q4f16_1-MLCTinyLlama-1.1B-Chat-v1.0-q4f32_1-MLCTinyLlama-1.1B-Chat-v1.0-q4f16_1-MLC-1kTinyLlama-1.1B-Chat-v1.0-q4f32_1-MLC-1kLlama-3.2-1B-Instruct-q0f16-MLCLlama-3.2-1B-Instruct-q4f16_1-MLCLlama-3.2-1B-Instruct-q4f32_1-MLC
~1.5B parameters
phi-1_5-q4f16_1-MLCphi-1_5-q4f32_1-MLCphi-1_5-q4f16_1-MLC-1kphi-1_5-q4f32_1-MLC-1kQwen2-1.5B-Instruct-q4f16_1-MLCQwen2-1.5B-Instruct-q4f32_1-MLCQwen2-Math-1.5B-Instruct-q4f16_1-MLCQwen2-Math-1.5B-Instruct-q4f32_1-MLCQwen2.5-1.5B-Instruct-q4f16_1-MLCQwen2.5-1.5B-Instruct-q4f32_1-MLCQwen2.5-Coder-1.5B-Instruct-q4f16_1-MLCQwen2.5-Coder-1.5B-Instruct-q4f32_1-MLCQwen2.5-Math-1.5B-Instruct-q4f16_1-MLCQwen2.5-Math-1.5B-Instruct-q4f32_1-MLC
~1.6B parameters
stablelm-2-zephyr-1_6b-q4f16_1-MLCstablelm-2-zephyr-1_6b-q4f32_1-MLCstablelm-2-zephyr-1_6b-q4f16_1-MLC-1kstablelm-2-zephyr-1_6b-q4f32_1-MLC-1k
~1.7B parameters
SmolLM2-1.7B-Instruct-q4f16_1-MLCSmolLM2-1.7B-Instruct-q4f32_1-MLCQwen3-1.7B-q4f16_1-MLCQwen3-1.7B-q4f32_1-MLC
~2B parameters
gemma-2b-it-q4f16_1-MLCgemma-2b-it-q4f32_1-MLCgemma-2b-it-q4f16_1-MLC-1kgemma-2b-it-q4f32_1-MLC-1kgemma-2-2b-it-q4f16_1-MLCgemma-2-2b-it-q4f32_1-MLCgemma-2-2b-it-q4f16_1-MLC-1kgemma-2-2b-it-q4f32_1-MLC-1kgemma-2-2b-jpn-it-q4f16_1-MLCgemma-2-2b-jpn-it-q4f32_1-MLC
~2.7B parameters
phi-2-q4f16_1-MLCphi-2-q4f32_1-MLCphi-2-q4f16_1-MLC-1kphi-2-q4f32_1-MLC-1k
~3B parameters
RedPajama-INCITE-Chat-3B-v1-q4f16_1-MLCRedPajama-INCITE-Chat-3B-v1-q4f32_1-MLCRedPajama-INCITE-Chat-3B-v1-q4f16_1-MLC-1kRedPajama-INCITE-Chat-3B-v1-q4f32_1-MLC-1kHermes-3-Llama-3.2-3B-q4f16_1-MLCHermes-3-Llama-3.2-3B-q4f32_1-MLCLlama-3.2-3B-Instruct-q4f16_1-MLCLlama-3.2-3B-Instruct-q4f32_1-MLCMinistral-3-3B-Base-2512-q4f16_1-MLCMinistral-3-3B-Reasoning-2512-q4f16_1-MLCMinistral-3-3B-Instruct-2512-BF16-q4f16_1-MLCQwen2.5-3B-Instruct-q4f16_1-MLCQwen2.5-3B-Instruct-q4f32_1-MLCQwen2.5-Coder-3B-Instruct-q4f16_1-MLCQwen2.5-Coder-3B-Instruct-q4f32_1-MLC
~3.8B parameters
Phi-3-mini-4k-instruct-q4f16_1-MLCPhi-3-mini-4k-instruct-q4f32_1-MLCPhi-3-mini-4k-instruct-q4f16_1-MLC-1kPhi-3-mini-4k-instruct-q4f32_1-MLC-1kPhi-3.5-mini-instruct-q4f16_1-MLCPhi-3.5-mini-instruct-q4f32_1-MLCPhi-3.5-mini-instruct-q4f16_1-MLC-1kPhi-3.5-mini-instruct-q4f32_1-MLC-1kPhi-3.5-vision-instruct-q4f16_1-MLCPhi-3.5-vision-instruct-q4f32_1-MLC
~4B parameters
Qwen3-4B-q4f16_1-MLCQwen3-4B-q4f32_1-MLC
~7B parameters
DeepSeek-R1-Distill-Qwen-7B-q4f16_1-MLCDeepSeek-R1-Distill-Qwen-7B-q4f32_1-MLCHermes-2-Pro-Mistral-7B-q4f16_1-MLCLlama-2-7b-chat-hf-q4f16_1-MLCLlama-2-7b-chat-hf-q4f32_1-MLCLlama-2-7b-chat-hf-q4f16_1-MLC-1kLlama-2-7b-chat-hf-q4f32_1-MLC-1kMistral-7B-Instruct-v0.2-q4f16_1-MLCMistral-7B-Instruct-v0.3-q4f16_1-MLCMistral-7B-Instruct-v0.3-q4f32_1-MLCNeuralHermes-2.5-Mistral-7B-q4f16_1-MLCOpenHermes-2.5-Mistral-7B-q4f16_1-MLCQwen2-7B-Instruct-q4f16_1-MLCQwen2-7B-Instruct-q4f32_1-MLCQwen2-Math-7B-Instruct-q4f16_1-MLCQwen2-Math-7B-Instruct-q4f32_1-MLCQwen2.5-7B-Instruct-q4f16_1-MLCQwen2.5-7B-Instruct-q4f32_1-MLCQwen2.5-Coder-7B-Instruct-q4f16_1-MLCQwen2.5-Coder-7B-Instruct-q4f32_1-MLCWizardMath-7B-V1.1-q4f16_1-MLC
~8B parameters
DeepSeek-R1-Distill-Llama-8B-q4f16_1-MLCDeepSeek-R1-Distill-Llama-8B-q4f32_1-MLCHermes-2-Pro-Llama-3-8B-q4f16_1-MLCHermes-2-Pro-Llama-3-8B-q4f32_1-MLCHermes-2-Theta-Llama-3-8B-q4f16_1-MLCHermes-2-Theta-Llama-3-8B-q4f32_1-MLCHermes-3-Llama-3.1-8B-q4f16_1-MLCHermes-3-Llama-3.1-8B-q4f32_1-MLCLlama-3-8B-Instruct-q4f16_1-MLCLlama-3-8B-Instruct-q4f32_1-MLCLlama-3-8B-Instruct-q4f16_1-MLC-1kLlama-3-8B-Instruct-q4f32_1-MLC-1kLlama-3.1-8B-Instruct-q4f16_1-MLCLlama-3.1-8B-Instruct-q4f32_1-MLCLlama-3.1-8B-Instruct-q4f16_1-MLC-1kLlama-3.1-8B-Instruct-q4f32_1-MLC-1kQwen3-8B-q4f16_1-MLCQwen3-8B-q4f32_1-MLC
~9B parameters
gemma-2-9b-it-q4f16_1-MLCgemma-2-9b-it-q4f32_1-MLC
~13B parameters
Llama-2-13b-chat-hf-q4f16_1-MLC
~70B parameters (needs high-end GPU / lots of RAM)
Llama-3-70B-Instruct-q3f16_1-MLCLlama-3.1-70B-Instruct-q3f16_1-MLC
Embedding models (for semantic/vector search, not chat)
snowflake-arctic-embed-s-q0f32-MLC-b4snowflake-arctic-embed-s-q0f32-MLC-b32snowflake-arctic-embed-m-q0f32-MLC-b4snowflake-arctic-embed-m-q0f32-MLC-b32
To let players choose a model at runtime, use WebLLM::GetAvailableModels() which returns all supported IDs as a comma-separated string, then call Load Model with the chosen ID — the existing conversation context is preserved.
Demo project
A complete working demo scene is available as a paid download ($5). It includes:
- Full chat UI wired up to the LLM behavior
- Live loading progress bar with status text
- System prompt input so you can give the AI a persona
- Model switcher — change models mid-conversation without losing context
- Properly commented GDevelop events showing every feature of the extension
The demo is a ready-to-open GDevelop folder project. Great as a starting point or just to see how everything fits together.
License
The extension (webllm.json) is free to use in any project, commercial or otherwise.
The underlying WebLLM library is MIT licensed. Individual model weights are subject to their own licenses (Llama models require accepting Meta's license on Hugging Face, Gemma models require Google's license, etc.).
Download
Click download now to get access to the following files:
Leave a comment
Log in with itch.io to leave a comment.